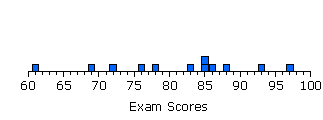
Dans son acception la plus simple, une distribution est une liste de mesures individuelles réalisée pour une variable déterminée. Pour faciliter la lecture, les résultats sont organisés de la valeur la plus faible à la valeur la plus forte. Par exemple, soient les notes obtenues par 12 étudiants lors d’un contrôle noté sur 100 :
61, 69, 72, 76, 78, 83, 85, 85, 86, 88, 93, 97
On peut au premier coup d’œil constater l’étendue de la distribution et la façon dont les notes sont réparties les unes par rapport aux autres. On peut faciliter l’intégration de l’information contenue dans cette distribution par une représentation graphique.
La représentation graphique la plus simple dans ce cas est l’histogramme
L’axe horizontal représente l’étendue de la distribution avec une graduation correspondant à l’unité de notation. Chaque note est placée à l’endroit ad hoc sous la forme d’un carré. Le type de graduation traduit l’idée d’échelle d’intervalles égaux qui semble convenir pour ce type de variable.
Ce type de graphe est utile pour obtenir une information sur chaque individu et chaque mesure de la distribution. Mais avec un nombre important d’individus, il perd de son intérêt.
Dans d’autres cas, l’allure générale de la distribution importe plus que les éléments individuels. Il convient alors d’adopter d’autres types de représentation graphique.
Histogramme, diagramme en baton, en tuyau d’orgue
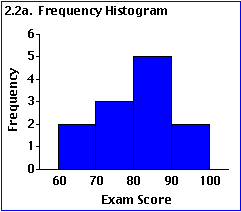
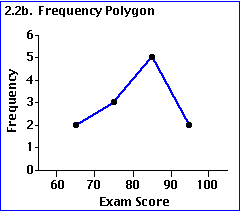
Polygone de fréquence : en principe pour les mesures continues.
Courbe de lissage : donne une image plus progressive des phénomènes.
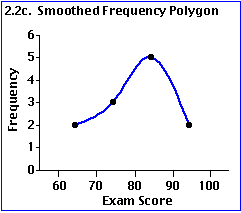
Les trois représentations ci-dessus ont pour principe de résumer l’information en divisant l’étendue de la mesure en intervalles égaux (ici tous les 10 points, un intervalle) et en comptant le nombre d’individus compris dans cet intervalle.
Les représentations ici présentées sont faites en fonction des fréquences absolues (observées) i.e. des nombres de cas observés. On aurait également pu choisir de représenter les fréquences relatives en passant par les pourcentages ou proportions.
Ce faisant, nous avons constitué des classes : en l’occurrence, 4 classes de valeurs.
Paramètres du grec " à côté de la mesure ". Avec le sens de définir une limite à la mesure.
Les paramètres d’une distribution sont les caractéristiques qui la définissent, qui en déterminent les limites.
Soient les résultats d’examen de six groupes en statistique. Ces résultats sont représentés par des polygones de fréquence lissés avec en abscisse les classes de notation et en ordonnée les fréquences relatives de résultats. La comparaison visuelle de ces 6 graphes fait apparaître des différences qui permettent de définir les 5 paramètres principaux d’une distribution.
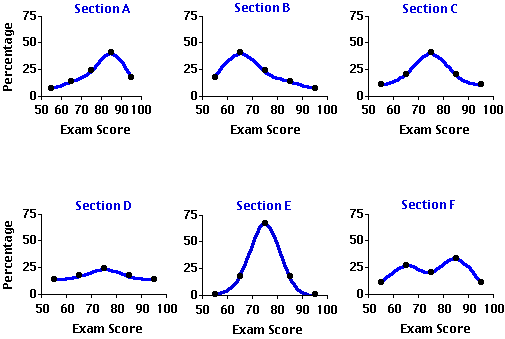
1. L’Asymétrie (skew) :
On parle de distribution asymétrique l(skewed) orsque les pentes de part et d’autre des valeurs les plus fortes ne sont pas de même inclinaison. On observe alors un effet d’asymétrie par rapport à un axe de symétrie qui serait constitué par la classe la plus représentée dans l’échantillon.
L’examen des sections A et B du graphe traduit un effet de symétrie en sens opposé. La section A présente une asymétrie négative (dont la pente faible = allongée s’étend vers la gauche (côté négatif d’un système d’axes). La section B une asymétrie positive, sa pente faible est orientée vers la droite
Une distribution symétrique (unskewed)présente des pentes de même inclinaison par rapport à sa classe la plus forte. C’est le cas des sections C, D, E.
2. L’Aplatissement (kurtosis) :
Du grec kurtosis : incurvation ou convexité.
Ce paramètre définit l’élévation plus ou moins forte de la distribution au regard de son étendue. Une distribution peut être " aplatie " ou " élancée ". Les distributions aplaties sont platykurtiques (cas de D). Les distributions élancées sont leptokurtiques (cas de E). Les distributions moyennes sont mésokurtiques (cas de C).
3. La modalité (modality)
La modalité fait référence au nombre de sommets distincts que l’on peut observer dans une courbe de distribution. Chaque pic constitue un mode. Avec un pic la distribution est unimodale, bimodale avec deux, trimodale pour 3, ou polymodale si plus. Les sections A, B, C, D et E ont des distributions unimodales. La section F est bimodales avec un premier mode entre 60 et 70 et un second mode entre 80 et 90.
L’existence de 2 ou plusieurs modes peut traduire la superposition dans un échantillon de deux populations ou plus, donc la superposition de 2 (ou +) distributions.
4. Mesure de la tendance centrale (Central tendency) :
La notion de tendance centrale traduit le fait qu’un nombre plus important de sujets (individus) présente les mêmes scores (nombre de classes réduit). Trois paramètres permettent de mesurer la tendance centrale.
Mode : le mode correspond au point où à la classe (classe modale) présentant le plus grand nombre d’individus.
Médiane (Median) : c’est le point situé à mi-parcours de la distribution (même nombre d’individus de valeur inférieure et de valeur supérieure à la valeur médiane).
Moyenne (Mean) : c’est la moyenne arithmétique des mesures de tous les individus (N). La moyenne est = Somme de toutes les valeurs/nombre de valeurs
Mx = Somme (x1 …xn)/N =
Ces trois paramètres coïncident (sont superposés) lorsque la distribution est unimodale et parfaitement symétrique. Dans les distributions asymétriques (skewed) les trois paramètres sont plus ou moins éloignés mes uns des autres. Leur position relative (séquence) dépend de la forme d’asymétrie (figure).
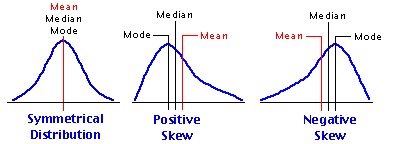
5. Mesure de la variablilité :
La notion de variabilité traduit la tendance des mesures à se disperser les unes par rapport aux autres (grand nombre de classes).
Etendue (range) : espace entre la valeur la plus forte et la valeur la plus faible.
Interquartile : distance entre les valeurs extrèmes pour la moitié centrale des scores dans la distribution.
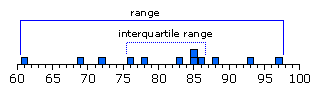
Ces deux paramètres de la variabilité ne peuvent convenir que pour des objectifs strictement descriptifs. Les deux paramètres suivants sont bien plus intéressants.
Ecart à la moyenne (deviate) : xi - Mx ; ce paramètre n’est pas intéressant en soi car leur somme est égale à zéro dans une distribution.
Carré des écarts à la moyenne = (xi - Mx )2
Somme des carrés des écarts à la moyenne = S(xi - Mx ) 2
Variance : La variance est la moyenne des carrés des écarts à la moyenne
Ecart type (standard deviation). C’est la racine carrée de la variance.
Nota : dans le calcul de la variance ou de l’Ecart type, la valeur du dénominateur est N lorsque le calcul s’effectue sur un échantillon. Lorsque le calcul concerne une population, on utilise (N-1).
L’écart-type est le paramètre le plus généralement utilisé pour rendre compte de la variabilité d’une distribution car intuitivement il se comprend mieux étant exprimé dans la même unité que les mesures constituant la population (par exemple des m ou des kg ; alors que la variance s’exprime en unité au carré soit des m2 ou des kg2 ! ! !).
La distribution considérée pourra alors être résumée par un paramètre de position ou de tendance centrale comme la moyenne ET par un paramètre de variabilité ou de dispersion comme l’écart-type : dans notre exemple de notes de 12 élèves : on aura une moyenne de 81,08 ± 9,87, la quantité écart-type pouvant s’ajouter ou se soustraire à la moyenne. La valeur de référence de cetet distribution, réduite à ± 1z, s’étend donc de 71,21 à 90,95. Cette marge correspond donc aux 2/3 des valeurs individuelles observées.
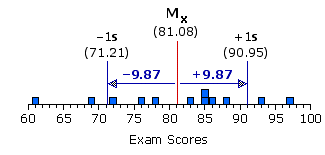
La valeur ± 1 écart type représente un domaine (une étendue) dans la distribution, centré sur la moyenne. Il concerne les 2/3 des individus lorsque la distribution n’est pas fortement asymétrique.
La variabilité introduit nécessairement la notion de probabilité d’occurrence d’un fait, d’une valeur. Ceci est important pour gérer toute action visant à prédire des relations générales concernant un grand effectif (une population) à partir de la mesure d’un effectif réduit (un échantillon).
1. Définitions
Distribution empirique : ce sont les distributions issues de collecte de données (échantillon) ou extrapolée à partir de mesures à l’ensemble d’une population : par exemple : le taux de cholestérol d’un échantillon de 100 citoyens et celui de la population française sont des distributions empiriques.
Distribution théorique : est issue de principes ou d’hypothèses dans le cadre d’un raisonnement mathématique impliquant une séquence plus ou moins complexe de conditions de la forem " si tel et tel est vrai, alors ceci et cela est également vrai ". En général, le processus de statistique inférentielle commence par une ou plusieurs distributions empiriques et se termine en faisant référence à l’une ou l’autre des distributions théoriques de probabilité.
2. Une forme particulière de distribution : la distribution normale théorique
Ou courbe en cloche .
On ne peut se dispenser de présenter le modèle de distribution théorique le plus fréquemment cité dans la littérature statistique : la distribution normale ou loi normale.
Cette distribution se traduit graphiquement par une courbe en forme de cloche (figure). Il ne s’agit pas ici d’un polygone d efréquence lissé et " parfait " issu d’une distribution empirique, mais d’une abstraction mathématique, généré (issue de) une formule appelée fonction normale de densité de probabilité (normal probability density function). Nos précurseurs en statistiques ont fait toutes les démonstrations nécessaires pour asserter de l’intérêt et des propriétés de cette fonction de distribution et nous n’y ajouterons rien. Considérons que la figure représente une distribution de fréquence abstraite.
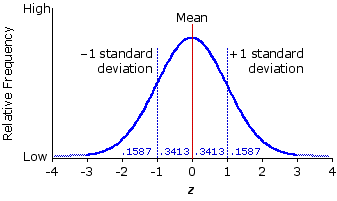
L’axe vertical décrit les fréquences relatives de la distribution, soit en pourcentage, soit en proportions.
L’axe horizontal est gradué en unités de z, c’est à dire en partant de la valeur centrale (moyenne) on porte 1, 2, … z vers la droite ou vers la gauche —1, -2 ou .. z
La valeur moyenne (z=0) est placée exactement au centre, et + ou — un écart type (-1z et +1z) délimite exactement une surface correspondant à 68,26 % de la distribution totale (environ les 2/3) avec exactement "34,13% de part et d’autre de la moyenne. Le reste de la distribution (soit 31,74%) est symétriquement réparti à droire et à gauche de —1z et +1z (15,87%)
Nous avons là une des propriétés les plus évidentes de la loi normale de distribution. Nous en reparlerons plus loin.
Le succès de cette loi (courbe) tient au fait que de très nombreuses distributions empiriques se révèlent proche d’elle.
3. Distributions empiriques : populations et échantillons
Il est particulièrement intéressant d’appliquer les distributions théoriques aux relations entre populations et échantillons. Sur un plan statistique, cette distinction est celle qu’il y a entre TOUT et UN PEU.
Lorsque l’on peut mesurer TOUS les représentants d’une variable déterminée, on obtient une distribution de population.
En statistique, la notion de population fait référence à l’ensemble des représentatnts d’un item sur lequel porte la mesure (personnes, objets, éléments, notes, résultats, etc.).
L’échantillon est une fraction " représentative " de cette population.
Très généralement, les questions que l’on se pose à propos d’une population ne pourront être résolue par la mesure de l’ensemble des représentants de celle-ci : trop nombreux, inaccesssibles, ou opération trop coûteuse.
o Par exemple, peut-on étudier la distribution de la taille dans une population de poissons comme les morues ? Il faudra alors se contenter de mesurer les variables concernées sur un échantillon. Cela posera le problème de savoir comment cet échantillon sera défini.
o Pour un institut de sondage, la population étudiée est un ensemble d’hommes et de femmes occupant une portion définie de l’espace (pays, région, commune) et jouant un rôle socio-économique (âge, sexe, revenus). Un échantillon représentatif sera un nombre limité mais réunissant les (des) éléments caractéristiques de la distribution (supposée) de la population concernée. Pour définir l’opinion de la France sur un sujet donné, un échantillon de 1000 à 1200 individus pourrait représenter une population de 60 millions d’habitants.
o Dans l’étude des qualités de l’eau d’un bassin hydrographique, la population est constituée par tout le volume d’eau qui circule dans le réseau et qu’il est hors de question de mesurer en totalité. L’échantillon représenattif sera constitué par les 20 (ou n) prélèvements de 10 (ou x) cm3 que l’on va analyser.
L’échantillonnage sera l’ensemble des opérations permettant de prélever dans une population les individus qui vont constituer l’échantillon.
Un échantillon est dit aléatoire ou prélevé au hasard lorsque tous les individus de la population ont une meême probabilité de faire partie de l’échantillon. Différents procédés permettent d’assurer le caractère aléatoire des échantillons. Le plus courant est l’emploi de tirages de nombres aléatoires (ou de tables de nombres aléatoires) (cf. manuels de statistique).
Par exemple, si l’on veut mesurer la pollution d’un étang dont on possède le plan, il conviendra d’établir un quadrillage de sa surface. On déterminera ensuite à l’aide d’une table de nombres aléatoires les coordonnées du nombre voulu de points de prélèvement d’eau. On peut également utiliser la projection de " dés " sur le plan.
La définition de plans d’expérience aléatoires est une composante nécessaire de tout processus rationnel d’analyse des données. Il doit tenir compte des impératifs matériels (temps, effectifs, matériel dispo) et des moyens financiers affectés à l’opération.
Les opérations de statistique inférentielle ont pour objectif de tester des hypothèses permettant de ramener à toute une population des mesures faites sur un échantillon, par assimilation de la distribution de l’échantillon à celle de la population, en définissant une marge d’erreur acceptable.
Distribution des tailles (normale ?)
Distribution des feuilles ()
Exercices sur lois normales
Exercice sur série 02