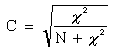
| et | 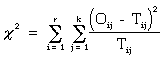
|
Nous souhaitons mettre en ûˋvidence les relations qui existent entre deux sûˋries d'observations (deux variables X et Y) considûˋrûˋes simultanûˋment. Nous voulons aussi connaûÛtre la nettetûˋ de leur liaison.
Il faut distinguer deux situations :
une des deux variables, la variable dûˋpendante, doit ûˆtre exprimûˋe en fonction de l’autre, la variable indûˋpendante, de faûÏon û prûˋvoir ou estimer l’une en fonction de l’autre. Les valeurs de la variable indûˋpendante sont fixûˋes par avance par l’expûˋrimentateur.
Exemples :
Ces questions peuvent ûˆtre abordûˋes avec les tests de rûˋgression.
Les deux variables ne peuvent ûˆtre distinguûˋes, et pourront prendre n’importe quelle valeur pour n’importe quel individu observûˋ. Les variables sont dites interdûˋpendantes.
Ces questions sont traitûˋes avec les tests de corrûˋlation.
Il est, dans ce cas, important de mesurer le degrûˋ de relation existant entre deux sûˋries d'observation (le coefficient de corrûˋlation), mais il est tout aussi important de pouvoir dûˋcider si une liaison observûˋe dans un ûˋchantillon indique ou non que les variables ûˋtudiûˋes sont probablement associûˋes dans la population û partir de laquelle a ûˋtûˋ extrait l'ûˋchantillon.
Quelques unes des mûˋthodes de mesure non paramûˋtriques de le corrûˋlation et leurs tests de signification seront prûˋsentûˋes.
Au prûˋalable, il ne faut jamais oublier que l'existence d'une corrûˋlation mûˆme ûˋlevûˋe entre deux sûˋries d'observations n'implique pas nûˋcessairement l'existence d'une relation de cause û effet (causalitûˋ) entre les deux variables considûˋrûˋes. En effet, les corrûˋlations observûˋes peuvent ûˆtre dues au fait que les variables ûˋtudiûˋes sont toutes deux soumises û des influences communes, modifiant simultanûˋment les valeurs, soit dans le mûˆme sens (corrûˋlation positive), soit en sens opposûˋs (corrûˋlation nûˋgative).
Ainsi, pour certaines exploitations agricoles, l'existence d'une corrûˋlation positive entre le revenu par unitûˋ de main d'œuvre et l'importance de la main d'œuvre n'implique pas qu'il suffit d'augmenter le nombre d'ouvriers pour amûˋliorer la rentabilitûˋ de l'exploitation. En rûˋalitûˋ, ces deux variables sont-elles mûˆmes fonction d'une troisiû´me variable : l'ûˋtendue des exploitations. La corrûˋlation observûˋe provient du fait que les grandes exploitations nûˋcessitent normalement une main d'œuvre plus nombreuse et qu'elles sont aussi ûˋconomiquement les plus rentables.
Ce coefficient de contingence C permet de mesurer l'intensitûˋ de la liaison existant entre deux variables. Il n'est intûˋressant que lorsque les observations de l'une ou des deux sûˋries sont mesurûˋes dans une ûˋchelle nominale.
Mûˋthode
Pour calculer ce coefficient entre deux sûˋries de catûˋgories (A1, A2,... Acet B1, B2,.... Br) nous arrangeons les frûˋquences en un tableau de contingence cô xô r.
| ô | A1 | A2 | ... | Ac | Total |
|---|---|---|---|---|---|
| B1 | (A1B1) | (A2B1) | .... | AcB1 | ô |
| B2 | (A1B2) | (A2B2) | .... | AcB2 | |
| - | ô | ô | ô | ô | |
| Br | (A1Br) | (A2Br) | .... | (AcBr) | |
| Total | ô | ô | ô | ô | N |
Dans ce tableau, nous pouvons entrer les frûˋquences thûˋoriques qui se produiraient s’il n'y avait pas de liaison ou de corrûˋlation entre les variables. Plus la divergence entre les frûˋquences attendues et les frûˋquences observûˋes est importante, plus le degrûˋ d'association entre ces deux variables est ûˋlevûˋ, et plus le coefficient de contingence C est ûˋlevûˋ.
Le coefficient C est dûˋfini comme suit :
|
| et |
|
oû¿
![]() nombre de cas observûˋs classûˋs dans la i(û´me) rangûˋe et la j(û´me) colonne.
nombre de cas observûˋs classûˋs dans la i(û´me) rangûˋe et la j(û´me) colonne.
![]() nombre de cas attendu, dans le cadre de l’hypothû´se nulle, classûˋs dans la i(û´me) rangûˋe et la j(û´me) colonne.
nombre de cas attendu, dans le cadre de l’hypothû´se nulle, classûˋs dans la i(û´me) rangûˋe et la j(û´me) colonne.
Exemple
Il est possible de rûˋutiliser les donnûˋes de l'exemple du khi carrûˋ pour k ûˋchantillons indûˋpendants vu prûˋcûˋdemment (dûˋpendance entre le cursus scolaire choisi par les adolescents d'une petite ville et leur appartenance û une classe sociale). Dans ce cas, c'est l'association entre les frûˋquences de sûˋries non ordonnûˋes (cursus scolaires) et les frûˋquences de sûˋries ordonnûˋes (appartenance sociale). Le tableau des donnûˋes est rûˋpûˋtûˋ ci-dessous :
| Classe | |||||
|---|---|---|---|---|---|
| Filiû´re | I et II | III | IV | V | Total |
| Prûˋpa U | 7,3 | 30,3 | 38,0 | 5,4 | 81 |
| 23 | 40 | 16 | 2 | ||
| Gûˋnûˋral | 18,6 | 77,5 | 97,1 | 13,8 | 207 |
| 11 | 75 | 107 | 14 | ||
| Commercial | 9,1 | 38,2 | 47,9 | 6,8 | 102 |
| 1 | 31 | 60 | 10 | ||
| Total | 35 | 146 | 183 | 26 | 390 |
Le khi carrûˋ calculûˋ û partir de ces donnûˋes est de 69,2. Nous pouvons alors dûˋterminer la valeur C du coefficient de contingence grûÂce û la formule prûˋcûˋdente :
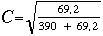
| = 0,39. |
La corrûˋlation, exprimûˋe par le coefficient de contingence, entre l'appartenance û une classe sociale et le choix d'un cursus scolaire dans cette ville est C = 0,39.
Test de la signification du coefficient de contingence
Si nous observons une corrûˋlation entre deux sûˋries de variables d'un ûˋchantillon, nous dûˋsirons savoir s'il est plausible de conclure que ces variables sont liûˋes entre elles dans la population reprûˋsentûˋe par l'ûˋchantillon.
Dans le cas du coefficient de contingence, nous calculons une valeur statistique qui donne une indication simple et adûˋquate de la signification de C. Cette statistique est le khi carrûˋ. Aussi suffit-il de dûˋterminer si le khi carrûˋ calculûˋ û partir de ces donnûˋes est significatif.
Si la probabilitûˋ d'obtenir le khi carrûˋ observûˋ, avec un degrûˋ de libertûˋ ûˋgal û (c -1) (r -1), est ûˋgal ou infûˋrieur û a l'hypothû´se nulle peut ûˆtre rejetûˋe û ce niveau de signification et nous pouvons conclure que, dans cette population, le degrûˋ d'association entre les deux sûˋries de variables n'est pas nul.
En reprenant l'exemple prûˋcûˋdent, nous avons montrûˋ que la relation entre le statut social et le cursus scolaire choisi est C = 0,39. Si nous considûˋrons que les adolescents de cette petite ville forment un ûˋchantillon alûˋatoire d'une population, nous pouvons tester si le statut social est reliûˋ au cursus scolaire choisi dans cette population en cherchant la signification du khi carrûˋ ûˋgal û 69,2. En se rûˋfûˋrant û la table des valeurs critiques du khi carrûˋ (table 2), nous pouvons dûˋterminer la probabilitûˋ associûˋe û ce khi carrûˋ pour un degrûˋ de libertûˋ de (c -1) (rô - 1) = (4 -1) (3 - 1) = 6. Cette probabilitûˋ est infûˋrieure û 0,001. Nous pouvons rejeter H0 û ce niveau de signification.
Nous concluons que le statut social et le choix d'un cursus scolaire dans une petite ville sont liûˋs dans la population de laquelle a ûˋtûˋ extraite cet ûˋchantillon d'adolescents.
Limitations du coefficient de contingence
Les coefficients de corrûˋlation doivent satisfaire û deux critûˋres : quand il y a absence complû´te d'association, le coefficient est ûˋgal û zero; quand les variables sont parfaitement en corrûˋlation, le coefficient devrait ûˆtre ûˋgal û 1. Le coefficient de contingence ûˋgal zûˋro en l'absence d'association, mais il ne peut atteindre l'unitûˋ dans la situation inverse, car sa limite supûˋrieure dûˋpend de la taille des colonnes c et des lignes r. Aussi, il n'est possible de comparer deux coefficients de contingence que lorsqu'ils proviennent de tables de contingence de mûˆme taille. Par ailleurs, le calcul de C implique celui du khi carrûˋ et donc impose les contraintes d'utilisation du khi carrûˋ.
Enfin, C n'est pas directement comparable û aucune autre mesure de corrûˋlation, r de Pearson, rs de Spearman ou ![]() de Kendall.
de Kendall.
Cependant, ce coefficient de contingence est extrûˆmement utile du fait de sa large applicabilitûˋ. Aucune contrainte d'application (forme de la population, continuitûˋ des variables, ûˋchelle de mesure) ne viennent restreindre son application.
C'est le premier test statistique rûˋalisûˋ û partir des rangs. Cette statistique est appelûˋe rûÇ ou rs. Elle mesure l'association entre deux variables mesurûˋes au moins dans une ûˋchelle ordinale.
Principe
Soit un groupe de lycûˋens rangûˋ d'une part selon leur classement au test de fin d'ûˋtude (X1, X2, ....Xn) et d'autre part au test de fin de premiû´re annûˋe û l'universitûˋ (Y1, Y2,...Yn), nous pouvons utiliser une mesure de corrûˋlation des rangs pour dûˋterminer la relation existant entre les X et les Y.
La corrûˋlation entre les rangs au test d'entrûˋe et ceux au test de fin de premiû´re annûˋe serait parfaite si Xi = Yi pour toutes les paires considûˋrûˋes. Aussi, un indice de disparitûˋ entre les deux ensembles de rangement pourrait ûˆtre la diffûˋrence entre les rangs de chaque paire : di = Xi - Yi. Ainsi, l'individu A a reûÏu le rang 1 au premier test et le rang 5 au second, la diffûˋrence est d = - 4. L'individu B rangûˋ 10û´me au premier test, est premier au second test, son d = +9. L'ampleur des diffûˋrents d donne une idûˋe de l'ûˋtroitesse de la relation entre les classements au premier et au second test. Si la relation entre les deux ensembles de rangs ûˋtait parfaite, chaque diffûˋrence d serait nulle. Donc, plus la diffûˋrence entre les rangs des deux variables est importante, moins leur relation est ûˋtroite.
Cependant, lors de la dûˋtermination de l'ampleur totale de la disparitûˋ entre les deux variables, il est prûˋfûˋrable d'utiliser di2 plutûÇt que di, dont les valeurs nûˋgatives rûˋduiraient les valeurs positives. Donc, plus les diffûˋrences di sont importantes, plus la valeur de la somme des di2 le sera aussi.
La meilleure formule pour calculer le coefficient rs de Spearman est :
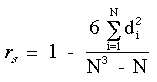
Mûˋthode
Aprû´s avoir listûˋ les N sujets, dûˋterminez le rang de X et de Y pour chaque variable. Dûˋterminez ensuite les diffûˋrences di entre les deux rangs, ûˋlevez au carrûˋ chaque di et sommez toutes les valeurs di2. Puis entrez cette somme et la valeur de N dans la formule de rs.
Exemple
La relation entre l'autoritarisme des ûˋtudiants et leur conformisme social est recherchûˋ. L'autoritarisme des sujets et leur conformisme social sont apprûˋciûˋs par le passage de tests. Les rûˋsultats obtenus û ces deux tests par chacun de 12 ûˋtudiants et leurs rangs (en italique) sont prûˋsentûˋs dans le tableau suivant :
| Etudiant | Apprûˋciations | di | di2 | |||
|---|---|---|---|---|---|---|
| de l'autoritarisme | du conformisme | |||||
| A | 82 | 2 | 42 | 3 | -1 | 1 |
| B | 98 | 6 | 46 | 4 | 2 | 4 |
| C | 87 | 5 | 39 | 2 | 3 | 9 |
| D | 40 | 1 | 37 | 1 | 0 | 0 |
| E | 116 | 10 | 65 | 8 | 2 | 4 |
| F | 113 | 9 | 88 | 11 | -2 | 4 |
| G | 111 | 8 | 86 | 10 | -2 | 4 |
| H | 83 | 3 | 56 | 6 | -3 | 9 |
| I | 85 | 4 | 62 | 7 | -3 | 9 |
| J | 126 | 12 | 92 | 12 | 0 | 0 |
| K | 106 | 7 | 54 | 5 | 2 | 4 |
| L | 117 | 11 | 81 | 9 | 2 | 4 |
| S di2=52 | ||||||
En appliquant la formule prûˋcedente, calcul de la valeur rs :
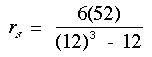
Observations ex-aequo
Quelquefois deux sujets ou plus peuvent avoir le mûˆme rang pour la mûˆme variable. Dans ce cas, chaque sujet reûÏoit la moyenne des rangs qui auraient ûˋtûˋ affectûˋs û chaque sujet s'il n'avait pas ûˋtûˋ ex-aequo.
Si le nombre d'ex-aequo n'est pas trop important, son effet sur rs est nûˋgligeable et la formule de calcul prûˋcedente peut ûˆtre utilisûˋe. Par contre, si le nombre d'ex-aequo est ûˋlevûˋ, un facteur de correction doit ûˆtre incorporûˋ au calcul de rs.
L'effet des rangs ex-aequo sur la variable X est de rûˋduire la somme des carrûˋs û une valeur infûˋrieure û
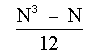
Il est donc nûˋcessaire de corriger la somme des carrûˋs. Le facteur de correction est T :
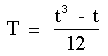
ou t = le nombre d'observations ex-aequo pour un rang donnûˋ. La somme des carrûˋs corrigûˋe pour les ex-aequo devient ;
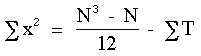
ST est la somme des diffûˋrentes valeurs T de tous les groupes d'observations ex-aequo.
De la mûˆme faûÏon, Sy2 est
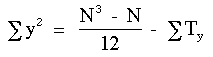
Lorsqu'il y a un nombre important d'ex-aequo, il faut alors utiliser la formule suivante pour calculer rs :
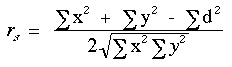
Exemple avec ex-aequo
L'autoritarisme et le conformisme social de 12 autres sujets sont apprûˋciûˋs par le passage de tests. Les rûˋsultats obtenus û ces deux tests par chacun de 12 ûˋtudiants et leurs rangs (en italique) sont prûˋsentûˋs dans le tableau suivant :
| Etudiant | Apprûˋciations | di | di2 | |||
|---|---|---|---|---|---|---|
| de l'autoritarisme | du conformisme | |||||
| A | 82 | 1,5 | 40 | 3 | -1,5 | 2,25 |
| B | 82 | 1,5 | 46 | 4 | 2,5 | 6,25 |
| C | 87 | 3,5 | 37 | 2 | 1,5 | 2,25 |
| D | 87 | 3,5 | 35 | 1 | 2,5 | 6,25 |
| E | 106 | 5 | 70 | 8 | -3,0 | 9,00 |
| F | 111 | 6 | 88 | 11 | -5,0 | 25,00 |
| G | 113 | 7 | 86 | 10 | -3,0 | 9,00 |
| H | 116 | 8 | 58 | 6 | 2,0 | 4,00 |
| I | 119 | 9 | 60 | 7 | 2,0 | 4,00 |
| J | 120 | 10,5 | 92 | 12 | -1,5 | 2,25 |
| K | 120 | 10,5 | 56 | 5 | -5,5 | 30,25 |
| L | 126 | 12 | 72 | 9 | 3 | 9,00 |
| S di2=109,50 | ||||||
Pour utiliser la formule de rs corrigûˋ pour les ex-aequo, nous calculons Sx2 et Sy2
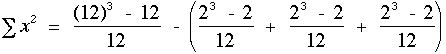
De la mûˆme faûÏon, on calcule Sy2
Ces valeurs reportûˋes dans la formule de rs corrigûˋe pur les ex-aequo donnent :
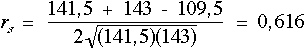
Si le calclul avait ûˋtûˋ rûˋalisûˋ sans tenir compte des ex-aequo, la valeur de rs serait de 0,617. L'effet d'ex-aequo peu nombreux est limitûˋ sur la valeur du coefficient de Spearman. Il peut, par contre, ûˆtre apprûˋciable lorsque les ex-aequo sont nombreux que ce soit pour la variable X ou pour la variable Y.
Signification de rs
Nous voulons savoir si les deux variables ûˋtudiûˋes ne sont pas liûˋes entre elles (hypothû´se nulle) et si la valeur observûˋe de rs diffû´re de zûˋro uniquement par hasard.
Pour les petits ûˋchantillons (4 Lorsque N est important (>10), la valeur rsest distribuûˋ comme la valeur statistique t de Student avec un degrûˋ de libertûˋ de N - 2. Donc aprû´s calcul du t, selon la formule prûˋcûˋdente, la signification de rs est celle de t. On l'obtient en se rûˋferant û la table des t.
Ainsi dans le premier exemple, le coefficient de corrûˋlation rs entre l'autoritarime et
le conformisme des ûˋtudiants de ce premier ûˋchantillon ûˋtait de 0,82. La table des valeurs critiques indique que cette valeur est significative au seuil 0,01 (test unilatûˋral). Nous pouvons rejeter l'hypothû´se nulle et conclure que l'autoristarisme et le conformisme sont sigtnificativement liûˋs.
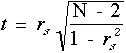
| Calculateur |
| Coefficient de corrûˋlation rs de Spearman |
Ce coefficient de corrûˋlation ![]() (tau) nûˋcessite que les variables soient mesurûˋes au moins dans une ûˋchelle ordinale, de telle sorte que chaque sujet des deux variables puisse ûˆtre rangûˋ. La distribution d'ûˋchantillonnage de
(tau) nûˋcessite que les variables soient mesurûˋes au moins dans une ûˋchelle ordinale, de telle sorte que chaque sujet des deux variables puisse ûˆtre rangûˋ. La distribution d'ûˋchantillonnage de ![]() , sous l'hypothû´se nulle, est connue, aussi le coefficient peut ûˆtre testûˋ pour sa signification.
, sous l'hypothû´se nulle, est connue, aussi le coefficient peut ûˆtre testûˋ pour sa signification.
Le mûˆme type de donnûˋes peuvent ûˆtre traitûˋs par le coefficient de corrûˋlation de Spearman rs (souvent plus connu). Mais le coefficient de Kendall prûˋsente l'avantage de pouvoir ûˆtre gûˋnûˋralisûˋ û un coefficient partiel de corrûˋlation ![]() xy.z et û un coefficient de concordance W.
xy.z et û un coefficient de concordance W.
Principe et mûˋthode
Si l'on demande û deux enseignants de ranger, par exemple, quatre dissertations (a, b, c, d) en fonction de la qualitûˋ de leur style. Leur classement est le suivant :
| Dissertation | a | b | c | d |
|---|---|---|---|---|
| Enseignant A | 3 | 4 | 2 | 1 |
| Enseignant B | 3 | 1 | 4 | 2 |
Lorsque les dissertations sont rûˋarrangûˋes de telle sorte que celles de l'enseignant 1 apparaissent rangûˋes dans l'ordre naturel, le tableau devient :
| Dissertation | d | c | a | b |
|---|---|---|---|---|
| Enseignant A | 1 | 2 | 3 | 4 |
| Enseignant B | 2 | 4 | 3 | 1 |
Il faut alors dûˋterminer combien de paires de rangs de l'enseignant B sont dans un ordre naturel l'un par rapport û l'autre. Ainsi, les rangs de la premiû´re paire 2 et 4 sont dans l'ordre naturel, 2 prûˋcû´de 4. On affecte alors la valeur + 1 û cette paire. Les rangs de la seconde paire 2 et 3 sont dans un ordre correct et obtiennent + 1. La troisiû´me paire (2 et 1) n'est pas dans un ordre correct et reûÏoit la valeur - 1. Il faut alors considûˋrer toutes les paires qui incluent le rang 4, puis le rang 3 et cette dûˋmarche nous permet de calculer la somme de tous les scores obtenus :
Maintenant, le total maximum possible qui peut ûˆtre atteint par les scores affectûˋs û l'ensemble des paires de jugements de l'enseignant B est obtenu lorsque tous les jugements des deux enseignants sont en parfait accord. Ce total maximum est le rûˋsultat de la combinaison de quatre choses prises deux û deuxô =ô 6.
Le degrûˋ de relation existant entre les deux sûˋries de rangs est alors indiquûˋ par le rapport du total des scores des rangements du juge B au total maximum possible :
Le total maximum de combinaisons de N objets pris deux û deux peut ûˆtre exprimûˋ par 1/2 N (N - 1), et le total observûˋ dans l'ûˋchantillon par S, alors la formule suivante :
| (A) |
oû¿ N = le nombre d'objets ou d'individus rangûˋs dans les deux sûˋries.
Le calcul de S peut ûˆtre simplifiûˋ de la faûÏon suivante. Quand les rangs d'un des juges sont dans l'ordre naturel, et que les rangs correspondants de l'autre juge sont dans le mûˆme ordre, la valeur de S est dûˋterminûˋe en partant du premier nombre sur la gauche et en comptant le nombre de rangs sur sa droite qui lui sont supûˋrieurs et en soustrayant de ce nombre, le nombre de rangs sur sa droite qui sont infûˋrieurs. Ainsi, lorsque les rangs de l'enseignant B sont 2, 4, 3, 1, û la droite du rang 2 sont les rangs 3 et 4 qui sont supûˋrieurs et le rang 1 qui est infûˋrieur. Le rang 2 contribue donc (+2 -1) = +1 û S. Pour le rang 4, aucun rang û sa droite n'est supûˋrieur, mais deux (les rangs 3 et 1) sont infûˋrieurs. Le rang 4 contribue donc de (0 - 2) = - 2 û S. Pour le rang 3, aucun rang sur la droite n'est supûˋrieur, mais un (le rang 1) est infûˋrieur, et donc le rang 3 participe de (0 - 1) = - 1 û S. Leur participation totale û S est donc :
S = (+1) + (-2) + (-1) = -2
Connaissant la valeur de S, il est possible de calculer la valeur observûˋe de :
|
| - 0,33 |
|---|
Exemple
La relation entre l'autoritarisme des ûˋtudiants et leur conformisme social est recherchûˋ. L'autoritarisme des sujets et leur conformisme social sont apprûˋciûˋs par le passage de tests. Les rûˋsultats obtenus û ces deux tests par chacun de 12 ûˋtudiants et leurs rangs (en italique) sont prûˋsentûˋs dans le tableau suivant :
| Etudiant | Apprûˋciations | |||
|---|---|---|---|---|
| de l'autoritarisme | du conformisme | |||
| A | 82 | 2 | 42 | 3 |
| B | 98 | 6 | 46 | 4 |
| C | 87 | 5 | 39 | 2 |
| D | 40 | 1 | 37 | 1 |
| E | 116 | 10 | 65 | 8 |
| F | 113 | 9 | 88 | 11 |
| G | 111 | 8 | 86 | 10 |
| H | 83 | 3 | 56 | 6 |
| I | 85 | 4 | 62 | 7 |
| J | 126 | 12 | 92 | 12 |
| K | 106 | 7 | 54 | 5 |
| L | 117 | 11 | 81 | 9 |
Nous rûˋarrangeons l'ordre des sujets de faûÏon û ce que l'ordre des rangs pour le conformisme social se prûˋsente dans l'ordre naturel :
| Sujet | D | C | A | B | K | H | I | E | L | G | F | J |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ô | ô | ô | ô | ô | ô | ô | ô | ô | ô | ô | ô | ô |
| Conformisme social | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| Autoritarisme | 1 | 5 | 2 | 6 | 7 | 3 | 4 | 10 | 11 | 8 | 9 | 12 |
Nous pouvons alors dûˋterminer la valeur de S :
S = (11 -0) + (7 -3) + (9 -0) + (6 - 2) + (5 - 2) + (6 -0) + (5 - 0) + (2 -2)
+ (1 -2) + (2 - 0) + (1 - 0) = 44
Connaissant S = 44 et N = 12 nous pouvons calculer
0,67 |
|---|
qui reprûˋsente le degrûˋ de relation entre l'autoritarisme et le conformisme social de 12 ûˋtudiants.
Observations ex-ûÎquo Quand deux observations ou plus ont la mûˆme valeur soit pour une variable soit pour l'autre, nous utilisons la procûˋdure habituelle : ces observations reûÏoivent le rang moyen des rangs qu'elles auraient eu si elles n'avaient pas ûˋtûˋ liûˋes. L'effet des ex-ûÎquo consiste û modifier le dûˋnominateur de la formule A
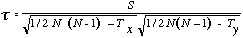
| (A’) |
L'effet correcteur est peu important.
Ainsi dans un ûˋchantillon de 12 observations, l'une des variables prûˋsente trois groupes de deux valeurs liûˋes, deux sujets sont ex-ûÎquo au rang 1,5, deux autres au rang 3,5 et deux au rang 10,5. Dans chaque cas, le nombre de valeurs ex-ûÎquo est t = 2 et nous calculons Ty:
Les valeurs suivantes sont observûˋes S = 25 et N = 12, Ty = 3 et Tx = 0, nous pouvons alors dûˋterminer la valeur de
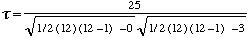
| = 0,39 |
Si la correction n'avait pas ûˋtûˋ rûˋalisûˋe, en utilisant la formule A, nous aurions trouvûˋ
Test de signification
Si un ûˋchantillon est tirûˋ d'une population dans laquelle deux variables X et Y ne sont pas liûˋes, et que les membres de l'ûˋchantillon sont rangûˋs pour X et Y, alors pour tout ordre donnûˋ des rangs de X, tous les ordres possibles des rangs de Y sont ûˋgalement observables.
Supposons que les rangs de X soient arrangûˋs selon leur ordre naturel 1, 2, 3, ...., N. Pour cet arrangement des rangs de X, tous les N ! ordres possibles des rangs de Y sont ûˋgalement probables sous H0. Par consûˋquent, tout ordre particulier des rangs de Y a une probabilitûˋ associûˋe de 1/ N!. Il est donc possible de calculer des tables de probabilitûˋs pour chaque valeur de N. Cependant, cette mûˋthode devient rapidement fastidieuse quand N augmente. Mais, quand N ãË 8, la distribution d'ûˋchantillonnage de ![]() est pratiquement comparable û celle de la distribution normale et la table de z (table 1) peut ûˆtre utilisûˋe.
est pratiquement comparable û celle de la distribution normale et la table de z (table 1) peut ûˆtre utilisûˋe.
Quand N est infûˋrieur ou ûˋgal û 10, la table des valeurs critiques de S du coefficient de corrûˋlation de Kendall donne les probabilitûˋs exactes d'obtenir un S donnûˋ (unilatûˋral). Si p est ûˋgal ou supûˋrieur û a, H0 peut ûˆtre rejetûˋe.
Quand N est supûˋrieur û 10, ![]() peut ûˆtre considûˋrûˋ comme normalement distribuûˋ avec une moyenne = 0
peut ûˆtre considûˋrûˋ comme normalement distribuûˋ avec une moyenne = 0
et un ûˋcart-type | 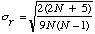 . .
| Alors | 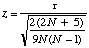 |
|---|
Il faut alors dûˋterminer la signification de z par rûˋfûˋrence û la table des z (Table 1).
Maintenant, les logiciels statistiques donnent la probabilitûˋ exacte (corrigûˋe pour les ex-ûÎquo) d’obtenir sous H0 le z correspondant aux donnûˋes. L’hypothû´se nulle est alors rejetûˋe si la probabilitûˋ exacte est ûˋgale ou infûˋrieure au seuil de signification a choisi.
Exemple pour un ûˋchantillon de taille supûˋrieure û 10
Nous avons d'ores et dûˋjû calculûˋ la corrûˋlation existant entre l'autoritarisme et le conformisme chez 12 ûˋtudiants ![]() = 0,67.
= 0,67.
| Nous pouvons calculer | 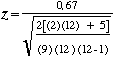 | = 3,03 |
La table des z montre que z ûˋgal ou supûˋrieur û 3,03 a une probabilitûˋ associûˋe de pô =ô 0,0012. Nous pouvons rejeter H0 û ce niveau de signification, et conclure que les deux variables sont associûˋes dans la population û partir de laquelle l'ûˋchantillon a ûˋtûˋ extrait.
Exercice :
1. Calculer le coefficient de corrûˋlation de Kendall et sa signification û partir des donnûˋes sur la longueur du corps et la profondeur de poitrine chez les vaches laitiû´res (![]() =0,39 ; z = 2,57 ; p = 0,0101).
=0,39 ; z = 2,57 ; p = 0,0101).
Comparez ces rûˋsultats avec ceux qui sont obtenus sur les mûˆmes donnûˋes par le test de corrûˋlation de Bravais-Pearson.
2. Deux experts, classant sûˋparûˋment 10 ûˋchantillons de cidre, ont donnûˋ les ordres de prûˋfûˋrence suivants :
| 1er expert | 2û´me expert |
|---|---|
Calculer le coefficient de corrûˋlation, et concluez.
Le coefficient de corrûˋlation de Spearman et celui de Kendall, bien que numûˋriquement diffûˋrents pour le mûˆme ensemble de donnûˋes, ont un pouvoir identique de rejet de H0.
Quand une corrûˋlation est observûˋe entre deux variables, il y a toujours la possibilitûˋ que cette corrûˋlation soit due û l'association entre chacune des deux variables et une troisiû´me variable.
Les effets de variation due û une troisiû´me variable sur la relation entre deux autres variables X et Y sont ûˋliminûˋs par une corrûˋlation partielle. D'une autre faûÏon, la corrûˋlation entre X et Y est calculûˋe alors que la troisiû´me variable est maintenue constante.
En rûˋalisant le protocole d'une expûˋrience, nous avons l'alternative soit d'introduire des contrûÇles expûˋrimentaux de faûÏon û ûˋliminer l'influence d'une troisiû´me variable soit d'utiliser des mûˋthodes statistiques pour ûˋliminer cette influence. Nous prûˋsentons une mûˋthode de contrûÇle statistique qui peut ûˆtre utilisûˋe avec le coefficient de corrûˋlation de Kendall.
Principe
Supposons que trois variables (X, Y, Z) sont mesurûˋes sur 4 sujets. Nous dûˋsirons dûˋterminer la corrûˋlation entre X et Y quand Z est maintenu constant. Les rangs des variables sont
| Sujet | a | b | c | d |
|---|---|---|---|---|
| rangs de Z | 1 | 2 | 3 | 4 |
| rangs de X | 3 | 1 | 2 | 4 |
| rangs de Y | 2 | 1 | 3 | 4 |
Le nombre de paires de rangs possible de chaque variable est de 4 pris deux û deux. Ayant rangûˋs les rangs de Z dans l’ordre naturel, nous observons chaque paire possible des rangs de X, des rangs de Y et des rangs de Z. Nous donnerons un signe + û chacune des paires pour lesquelles le rang le plus bas prûˋcû´de le plus hautô ; et un signe - û chacune des paires pour lesquelles le rang le plus ûˋlevûˋ prûˋcû´de le rang le plus bas.
| paire | (a, b) | (a, c) | (a, d) | (b, c) | (b, d) | (c, d) |
|---|---|---|---|---|---|---|
| Z | + | + | + | + | + | + |
| X | - | - | + | + | + | + |
| Y | - | + | + | + | + | + |
Ainsi, pour la variable X, le score pour la paire (a,b) est moins car les rangs de a et b, 3 et 1, ne sont pas dans l'ordre naturel.
Nous allons maintenant rûˋsumer l'information dans un tableau û double entrûˋe :
| Paires de Y dont le signe concorde avec celui de Z | Paires de Y dont le signe ne concorde pas avec celui de Z | Total | |
|---|---|---|---|
| Paires de X dont le signe concorde avec celui de Z | A 4 | B 0 | 4 |
| Paires de X dont le signe ne concorde pas avec celui de Z | C 1 | D 1 | 2 |
| Total | A+C = 5 | B+D = 1 | 6 |
Considûˋrons les trois signes sous (a,b). Pour cet ensemble de rangs, X et Y ont tous deux un signe - alors que Z a un signe +. X et Y sont en dûˋsaccords avec Z. Cette information est placûˋe dans la cellule D. Si l'on considû´re la paire (a, c), le signe de Y est en accord avec celui de Z, mais le signe de X est en dûˋsaccord avec celui de Z. Ainsi, cette information est assignûˋe û la cellule C. Dans chaque cas des paires restantes, le signe de Y et celui de X sont en accord avec celui de Z, les 4 paires sont placûˋes dans la cellule A du tableau. Le coefficient de rang partiel de Kendall est calculûˋ û partir de ce tableau.
Il est dûˋfini comme
| (B) |
Dans l'exemple des 4 objets considûˋrûˋs prûˋcûˋdemment,
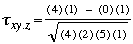
| = 0,63 |
Le coefficient de corrûˋlation entre X et Y lorsque Z est maintenu constant (![]() ) est de 0,63.
) est de 0,63.
Si nous avions calculûˋ la corrûˋlation entre X et Y sans considûˋrer l'effet de Z, nous aurions trouvûˋ ![]() = 0,67. Ceci suggû´re que les relations entre X et Z et entre Y et Z n'influencent que faiblement la relation observûˋe entre X et Y. Ce type d'infûˋrence doit ûˆtre fait avec certaines rûˋserves, û moins d'avoir des donnûˋes pertinentes permettant de supposer quel effet est observûˋ.
= 0,67. Ceci suggû´re que les relations entre X et Z et entre Y et Z n'influencent que faiblement la relation observûˋe entre X et Y. Ce type d'infûˋrence doit ûˆtre fait avec certaines rûˋserves, û moins d'avoir des donnûˋes pertinentes permettant de supposer quel effet est observûˋ.
La formule (B) est parfois appelûˋe le coefficient phi, et il peut ûˆtre montrûˋ que
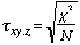
La prûˋsence du c2 dans cette expression suggû´re que ![]() mesure le degrûˋ d'accord entre X et Y indûˋpendamment de leur accord avec Z.
mesure le degrûˋ d'accord entre X et Y indûˋpendamment de leur accord avec Z.
Mûˋthode
La mûˋthode de calcul de ![]() devient rapidement fastidieuse lorsque N augmente. Kendall a montrûˋ que
devient rapidement fastidieuse lorsque N augmente. Kendall a montrûˋ que
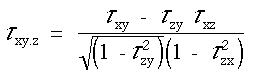
| (C) |
Exemple
Nous avons vu que la corrûˋlation entre l'autoritarisme et le conformisme social est de ![]() = 0,67.
= 0,67.
Mais il existe aussi une corrûˋlation entre le conformisme social et la conformitûˋ û la pression des groupes de ![]() = 0,39.
= 0,39.
Ceci nous fait nous demander si la premiû´re corrûˋlation ne reprûˋsente pas simplement l'intervention d'une troisiû´me variable : la conformitûˋ aux groupes de pression.
Nous pouvons tester cette hypothû´se en calculant le coefficient de corrûˋlation partiel entre autoritarisme et le conformisme social, en maintenant constant l'effet du besoin de cûˋder û la pression des groupes.
Les rûˋsultats sont prûˋsentûˋs dans le tableau suivant :
| ô | Rangs | ||
|---|---|---|---|
| Sujet | Conformisme | Autoritarisme | Conformitûˋ |
| ô | X | Y | Z |
| A | 3 | 2 | 1,5 |
| B | 4 | 6 | 1,5 |
| C | 2 | 5 | 3,5 |
| D | 1 | 1 | 3,5 |
| E | 8 | 10 | 5 |
| F | 11 | 9 | 6 |
| G | 10 | 9 | 7 |
| H | 6 | 3 | 8 |
| I | 7 | 4 | 9 |
| J | 12 | 12 | 10,5 |
| K | 5 | 7 | 10,5 |
| L | 9 | 11 | 12 |
Nous connaissons dûˋjû ![]() = 0,67 et
= 0,67 et ![]() = 0,39 et nous pouvons calculer
= 0,39 et nous pouvons calculer ![]() = 0,36. Nous pouvons alors dûˋterminer la valeur de
= 0,36. Nous pouvons alors dûˋterminer la valeur de ![]() en utilisant la formule (C)
en utilisant la formule (C)
| = 0,62 |
Le coefficient de corrûˋlation partiel entre autoritarisme et conformisme social est de 0,62. Cette valeur est peu diffûˋrente de celle de ![]() = 0,67. Nous pouvons conclure que la relation entre l'autoritarisme et le conformisme social (mesurûˋs avec ces ûˋchelles) est relativement indûˋpendante de l'influence de la conformitûˋ û un groupe de pression.
= 0,67. Nous pouvons conclure que la relation entre l'autoritarisme et le conformisme social (mesurûˋs avec ces ûˋchelles) est relativement indûˋpendante de l'influence de la conformitûˋ û un groupe de pression.
Test de signification
La distribution d'ûˋchantillonnage du coefficient de corrûˋlation partiel de Kendall n’est pas connue et donc aucun test de signification n'est possible.
Quand on dispose, non pas de deux, mais de k distributions d'une mûˆme sûˋrie d'individus en deux classes, la notion de corrûˋlation de rang peut ûˆtre gûˋnûˋralisûˋe grûÂce au coefficient de concordance. W exprime le degrûˋ d'association entre k variables.
Principe
Supposons que l'on demande û trois cadres de sociûˋtûˋs d’interviewer 6 demandeurs d'emploi et de les ranger sûˋparûˋment suivant leurs capacitûˋs û remplir le poste vacant. Les trois sûˋries indûˋpendantes de rangs donnûˋes par les trois cadres A, B, C sont exposûˋes dans le tableau suivant :
| Postulant | ||||||
|---|---|---|---|---|---|---|
| a | b | c | d | e | f | |
| Cadre A | 1 | 6 | 3 | 2 | 5 | 4 |
| Cadre B | 1 | 5 | 6 | 4 | 2 | 3 |
| Cadre C | 6 | 3 | 2 | 5 | 4 | 1 |
| Rj | 8 | 14 | 11 | 11 | 11 | 8 |
Si les trois cadres avaient ûˋtûˋ en parfait accord sur leur jugement des postulants, c'est-û -dire, s'ils les avaient rangûˋs dans le mûˆme ordre, alors l'un des postulants aurait reûÏu trois rangs 1 et sa somme de rangs serait de 3 = k. Le postulant suivant serait affectûˋ de la somme de rangs de 6 = 2 k et le moins performant des postulants serait affectûˋ de la somme de rangs de 18 = 6 k = N k. En gûˋnûˋral, quand il y a accord parfait parmi les k sûˋries de rangements, nous obtenons, pour les sommes des rangs, les sûˋries k, 2k, 3k....Nk.
D'un autre cûÇtûˋ, s'il n'y avait aucun accord parmi les cadres, les diffûˋrentes sommes des rangs seraient approximativement ûˋgales. W, le coefficient de concordance, est une fonction de ce degrûˋ de variation.
Mûˋthode
Pour calculer W, nous cherchons la somme des rangs, Rj , de chaque colonne du tableau k x N. Puis, nous sommons les Rj et divisons cette somme par N pour obtenir la valeur moyenne de Rj. Enfin, nous calculons les dûˋviations entre chaque Rj et la valeur moyenne et nous sommons les carrûˋs de ces dûˋviations s.
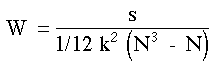 (D)
(D)oû¿ s = somme des carrûˋs des dûˋviations entre les Rj observûˋs et la moyenne de ces Rj.
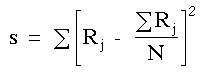
k = nombre de sûˋries de rangements, nombre de juges.
N = nombre d'individus rangûˋs
1/12 k2 (N3 - N) = la somme s que l'on obtiendrait dans le cas d'un accord parfait entre les k rangements.
û partir des donnûˋes prûˋcûˋdentes :
s = (8 -10,5)2 + (14 - 10,5)2 + (11 - 10,5)2 + (11- 10,5)2 + (11 - 10,5)2 + (8 - 10,5)2= 25,5
| et | 0,16 |
Exemple
Kendall a donnûˋ un exemple oû¿ 10 objets sont rangûˋs chacun pour 3 variables diffûˋrentes X, Y, Z. Les rangs obtenus sont les suivants :
| Variable | a | b | c | d | e | f | g | h | i | j |
|---|---|---|---|---|---|---|---|---|---|---|
| X | 1 | 4,5 | 2 | 4,5 | 3 | 7,5 | 6 | 9 | 7,5 | 10 |
| Y | 2,5 | 1 | 2,5 | 4,5 | 4,5 | 8 | 9 | 6,5 | 10 | 6,5 |
| Z | 2 | 1 | 4,5 | 4,5 | 4,5 | 4,5 | 8 | 8 | 8 | 10 |
| Rj | 5,5 | 6,5 | 9 | 13,5 | 12 | 20 | 23 | 23,5 | 25,5 | 26,5 |
La moyenne des Rj est 16,5.
s = (5,5 - 16,5)2 + (6,5 - 16,5)2 + (9 - 16,5)2 + (13,5 - 16,5)2 + (12 - 16,5)2 + (20 - 16,5)2 + (23 - 16,5)2 + (23,5 - 16,5)2+ (25,5 - 16,5)2 + (26,5 - 16,5)2= 591
Comme la proportion d'ex-ûÎquo est importante, une correction est apportûˋe au calcul de W.
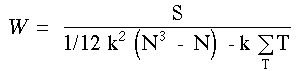
| (E) |
| oû¿ | correspond û la somme des valeurs de T pour l’ensemble des ex-ûÎquo |
| et | 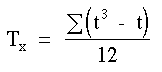
| et | 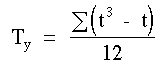 |
| pour le rangement de X : | = 1 |
| pour le rangement de Y : | = 1,5 |
| pour le rangement de Z : | = 7 |
| = 0,828 |
Test de signification de W
Petits ûˋchantillons
La distribution de s a ûˋtûˋ calculûˋe et certaines valeurs critiques tabulûˋes (Table des valeurs critiques de s pour le coefficient de concordance ; Table 13) pour des W significatifs aux seuils 0,05 et 0,01. Cette table est applicable pour k de 3 û 20 et N de 3 û 7.
Lorsqu’une valeur observûˋe de s est ûˋgale ou supûˋrieure û celle de la table pour un niveau de signification donnûˋ, alors Ho peut ûˆtre rejetûˋ û ce niveau de signification.
Dans le cas des 3 cadres jugeant 6 postulants, leur accord ûˋtait de W = 0,16. Rûˋfûˋrence û la table prûˋcûˋdente rûˋvû´le que la valeur s associûˋe û ce W (s = 25,5) n'est pas significative.
Grands ûˋchantillons
Quand N est supûˋrieur û 7, l'expression donnûˋe par la formule suivante F est approximativement distribuûˋe comme un khi carrûˋ de ddl = N - 1
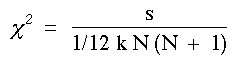
| ou = k (N -1) W (F) |
La probabilitûˋ associûˋe û ce c2 est dûˋterminûˋe par rûˋfûˋrence û la table du khi carrûˋ.
Si la valeur du c2 calculûˋe selon la formule F ûˋgale ou excû´de celle de la table du khi carrûˋ pour un niveau de signification et un degrûˋ de libertûˋ donnûˋe, l'hypothû´se nulle peut ûˆtre rejetûˋe û ce niveau de signification.